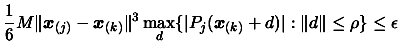Inside the optimization program, we only use polynomials of degree
lower or equal to 2. Therefore, we will always assume in the end
of this chapter that . We have thus
:
the maximum number of monomials inside
all the polynomials of the optimization loop.
A bound on the interpolation error.
We assume in this section that the objective function
, has its third derivatives that are bounded and continuous.
Therefore, if is any point int , and if is
any vector int that has
, then the
function of one variable
(3.26)
also has bounded and
continuous third derivatives. Further there is a least
non-negative number , independent of and , such
that every functions of this form have the property
(3.27)
This value of M is suitable for the following bound on the
interpolation error of f(x):
Interpolation Error =
(3.28)
Proof
We make any choice of . We regard as fixed for the moment,
and we derive a bound on
. The Taylor series
expansion of around the point is important.
Specifically, we let
, be the quadratic
polynomial that contains all the zero order, first order and
second order terms of this expansion, and we consider the
possibility of replacing the objective function by . The
replacement would preserve all the third derivatives of the
objective function, because is a quadratic polynomial.
Therefore, the given choice of M would remain valid. Further more,
the quadratic model that is defined by the interpolation
method would be . It follows that the error on the new
quadratic model of the new objective function is as before.
Therefore, when seeking for a bound on
in terms of
third derivatives of the objective function, we can assume without
loss of generality, that the function value , the gradient
vector
and the second derivative matrix
are all zero.
Let be an integer from
such that
, let be the vector:
(3.29)
and let
, be the function 3.28. The
Taylor series with explicit remainder formula gives:
(3.30)
where
depends on
and is in the interval
. The values of
, and are all zero due to the
assumptions of the previous paragraph, and we pick
. Thus expressions 3.31, 3.28,
3.32, 3.29 provide the bound
(3.31)
which also holds without
the middle part in the case
, because of the
assumption . Using again, we deduce from Equation
3.26 and from inequality 3.33, that the error
has the property:
Therefore, because is arbitrary, the bound of
equation
3.30 is true.
In the optimization loop, each time we evaluate the objective
function f, at a point , we adjust the value of an estimation
of using:
(3.32)
Validity of the interpolation in a radius of around
.
We will test the validity of the interpolation around
.
If the model (=the polynomial) is too bad around
, we
will replace the ``worst'' point
of the model by a
new,
better, point in order to improve the accuracy of the model.
First, we must determine . We select among the initial
dataset
a new dataset
which contains all the points
for which
. If is empty, the model is valid
and we exit.
We will check all the points inside , one by one.
We will begin by, hopefully, the worst point in : Among all the
points in
, choose the point the further away from
. We define as the index of such a point.
If is constrained by the trust region bound
, then the contribution to the error of the model from the
position
is approximately the quantity (using Equation
3.30):
(3.33)
(3.34)
Therefore the model is considered valid if it satisfies the
condition :
(3.35)
is a bound on the error which must be given to the
procedure which checks the validity of the interpolation. See
section 6.1 to know how to compute the bound
.
The algorithm which searches for the value of for which we
have
(3.36)
is described in Chapter 5.
We are ignoring the dependence of the other Newton polynomials in
the hope of finding a useful technique which can be implemented
cheaply.
If Equation 3.37 is verified, we now remove the point
from the dataset
and we iterate: we search among
all the points left in , for the point the further away from
. We test this point using 3.37 and continue
until the dataset
is empty.
If the test 3.37 fails for a point
, then we
change the polynomial: we remove the point
from the
interpolating set and replace it with the ``better'' point:
(were is the solution of 3.38): see
section 3.4.4, to know how to do.
Find a good point to replace in the interpolation.
If we are forced to include a new point in
the interpolation set even if the polynomial is valid, we must
choose carefully which point
we will drop.
Let us define
, the best (lowest) point of the
interpolating set.
We want to replace the point
by the point .
Following the remark of Equation 3.24, we must have:
as great as possible
(3.37)
We also wish to
remove a point which seems to be making a relatively large
contribution to the bound 3.30 on the error on the
quadratic model. Both of these objectives are observed by setting
to the value of that maximizes the expression:
(3.38)
Replace the interpolation point
by a new point .
Let
, be the new Lagrange
polynomials after the replacement of
by .
The difference
has to be a multiple of
, in order that
agrees with at
all the old interpolation points that are retained. Thus we deduce
the formula:
(3.39)
(3.40)
has to
be revised too. The difference
is a multiple of
to allow the old interpolation points to be
retained. We finally obtain:
(3.41)
Generation of the first set of point
.
To be able to generate the first set of interpolation point
, we need:
The base point
around which
A length which will be used to separate 2
interpolation point.
If we have already at disposal,
points situated
inside a circle of radius around
, we try
to construct directly a Lagrange polynomial using them. If the
construction fails (points are not poised.), or if we don't have
enough point we generate the following interpolation set:
First point:
From
to
:
(with
being a unit vector along the axis of the space)
Let us define :
From
to
:
From
to
:
Set .
For
For
Increment .
Translation of a polynomial.
The precision of a polynomial interpolation is better when all the
interpolation points are close to the center of the space (
are small).
Example: Let all the interpolation points
, be
near
, and
. We have constructed
two polynomials and :
interpolates the function at all the
interpolation sites
.
interpolates also the function at
all the interpolation sites
.
and are both valid interpolator of around
BUT it's more interesting to work with rather
then because of the greater accuracy in the interpolation.
How to obtain from ? is the polynomial after the translation
.
We will only treat the case where and are
quadratics. Let's define and the following way:
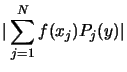
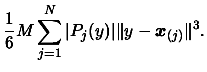
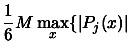
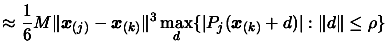
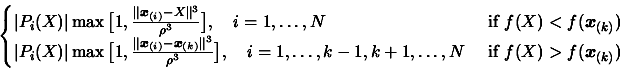
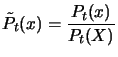
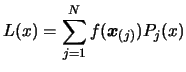 has to
be revised too. The difference
has to
be revised too. The difference

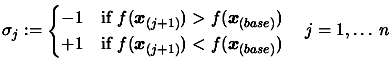
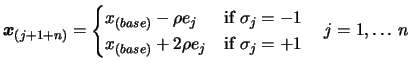
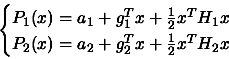
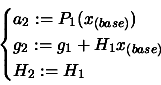
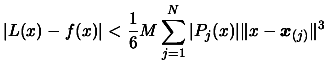
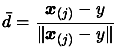
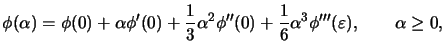
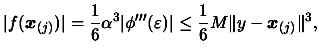
![$\displaystyle M_{new}= \max \bigg[ M_{old}, \frac{\vert L(x)-f(x)
\vert }{ \fr...
...sum_{j=1}^N \vert P_j(x) \vert \Vert x - \boldsymbol{x}_{(j)} \Vert^3 }
\bigg]$](img461.png)